|
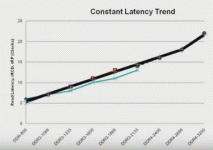
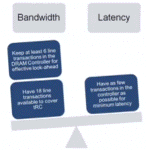
| DRAM traffic management | |
| .. |
| memory latency lessons
from SSD
market history |
The subtle indirectness of
relationship between raw memory latency and application performance in
enterprise environments was shown by the market lesson of how flash SSDs
displaced RAM SSDs in
over 99% of applications in a handful of years starting from the idea being
shown to work in user installations in 2004.
Looking back at that
period it's now clear that raw memory datasheet comparisons (between nand
flash and DRAM and SRAM too) were almost an insignificant factor.
The
success factors were:-
the lower cost per bit (which meant more
data could be sucked into the acceleration zone)
the applications
usefulness of read caching - compared to write caching (which minimized
the importance of flash's poor intrinsic R/W cell asymmetry)
and
the lower power consumption per bit of flash - which meant that huge numbers
of flash chips could be deployed in big controller pools to emulate high
random IOPS.
See also:-
sugaring flash
for the enterprise | | |
| .. |
 |
| .. |
DRAM technology won't
advance soon.
"We are hitting something of a lithography wall in
DRAM where shrinks are getting tougher and gains are not as attractive..." |
| Micron in SSD
news August 2013 | | |
| .. |
| "...Application-unaware
design of memory controllers, and in particular memory scheduling algorithms,
leads to uncontrolled interference of applications in the memory system" |
| Are you ready to
rethink RAM? | | |
| .. |
Even if you have a 3D
packaging technique which can pack more chips into a box - DRAM loses out to
nvm technologies which don't require refresh - when the scale of the installed
capacity (and watts) in the box is high.
If you can't fit enough RAM into the same single box then the memory
system accrues a box-hopping fabric-latency penalty which outweighs the benefits
of the faster raw memory chip access times inside the original box. |
| cool runnings... Rambus
to coach faster DRAM - April 2017 | | |
| .. |
| "At the technology
level, the systems we are building through continued evolution are not advancing
fast enough to keep up with new workloads and use cases. The reality is that
the machines we have today were architected 5 years ago, and ML/DL/AI uses in
business are just coming to light,
so the
industry missed a need." |
| From the blog -
Envisioning
Memory Centric Architecture by Robert Hormuth,
VP/Fellow and Server CTO - Dell
EMC (January 26, 2017) | | |
| .. |
| A new controller
architecture from Marvell - Final-Level Cache - brings the concept of tiered
RAM and DIMM wars down from the cloud to products like phones which operate at
battery scale. Using flash as RAM the company says can increase performance
even while while halving electrical power. |
| SSD news - May 2016 | | |
| .. |
| Plexistor says that its
Software-Defined Memory platform will support a wide range of memory and
storage technologies such as DRAM and emerging nvm devices such as NVDIMM-N and
3D XPoint as well as traditional flash storage devices such as NVMe and NVMe
over Fabric, enabling a scalable infrastructure to deliver persistent high
capacity storage at near-memory speed.
|
| SSD news - December
2015 | | |
| .. |
| Having SSDs located in a
DIMM socket in one server no longer precludes that very same data being
accessed by another server (with similar latency) as if it were just a locally
installed PCIe SSD. |
| ideas
linking Diablo and A3CUBE (September 2014) | | |
| .. |
 |
| .. |
| "There
is only one reason to buy SSD - performance!" |
...thus spake an ad on this site for the
RamSan-210 (a fast
rackmount SSD)
in 2002.
Since then we've found more
reasons (6 in total).
Only 6? - Doesn't sound much - but they gave birth to all the business plans
for all the SSDs in every market.
6 doesn't sound too difficult to
understand does it?
But analysis of SSD market behavior becomes
convoluted
in the enterprise
when you stir into the viable product permutations soup pot not only
the raw technology ingredients (memory, software architecture etc ) but also
throw in the seasoning desires of latent customer preferences.
| | |
... |
|
|
... |
| In the past we've always
expected the data capacity of memory systems (mainly DRAM) to be much smaller
than the capacity of all the other attached storage in the same data processing
environment. |
| cloud adapted
memory systems | | |
... |
 |
.... |
| Can you trust market
reports and the handed down wisdom from analysts, bloggers and so-called "industry
experts" any more than you can trust SSD benchmarks to tell you which
product is best?
|
| heck no! -
whatever gave you that silly idea? | | |
.. |
|
|
.... |
| After 2003 the only
technology which could displace an SSD from its market role was another SSD (or
SSD software). |
| SSD market
history | | |
.. |
|
Revisiting Virtual Memory - read the book |
Editor:- April 25, 2016 - One of the documents
I've spent a great deal of time reading recently is
Revisiting
Virtual Memory (pdf) - a PhD thesis written by Arkaprava Basu
a researcher at AMD.
My
search for such a document began when I was looking for examples of raw DRAM
cache performance data to cite in my blog - latency loving reasons for fading
out DRAM in the virtual memory slider mix (which you see on the left of this
page).
About a month after publishing it I came across
Arkaprava's "book" which not only satisfied my original information
gaps but also serves other educational needs too.
You can treat the
first 1/3 or so of his opus as a modern refresher for DRAM architecture which
also introduces the reader to several various philosophies related to DRAM
system design (optimization for power consumption rather than latency for
example) and the work includes detailed analysis of the relevance and efficiency
of traditional cache techniques within the context of large in-memory based
applications.
Among many other observations Arkaprava Basu says...
"Many big-memory workloads
a) Are long running,
b) Are sized to match memory capacity,
c) Have one (or a few) primary process(es)."
...read
the book (pdf) | | |
.. |
| What we've been seeing in
the enterprise PCIe SSD market in recent years is that most vendors are focusing
on making these products more affordable rather than trying to push the limits
of performance. |
| DIMM wars - the
Diablo Memory1 incident | | |
.. |
|
|
.. |
| Why can't SSD's true
believers agree on a single shared vision for the future of solid state
storage? |
| the SSD Heresies | | |
.. |
|
|
.. |
| As the possibilities for
deploying SSDs with application specific power, performance, and
storage/server/app optimimized role becomes better understood - modern systems
design groups are not only looking at designing their own SSDs (which has been
happening for years already) but also looking at deeply customizing the SSD in
their life - with customization which aims far beyond adding a few firmware
tweaks to a COTS SSD controller and choosing the flash to populate someone
else's reference design |
| aspects of SSD
design - the processors used inside and alongside | | |
.. |
|
|
.. |
|
|
..
..
.. |
| "The winners in SSD
software could be as important for data infrastructure as Microsoft was for
PCs, or Oracle was for databases, or Google was for search." |
| all enterprise data
will touch an SSD | | |
..
.. |
|
|